Event-Driven Microservices - Kafka and RabbitMQ
How can we achieve seamless communication in microservices? Event-driven architecture is the key to making that happen, by connecting services through events, systems can handle complex processes with ease, scale efficiently, and respond to changes in real time. Apache Kafka and RabbitMQ are tools commonly used for this purpose, both offer powerful features but serving different purposes. Choosing the right one is important, but for that we have to understand how both tools work and where they shine, that’s why I’m writing this post, to get a better understanding of these giants in the IT world.
What is Event-Driven Architecture?
Event-driven architecture (EDA) is a software design pattern where systems revolve around the production, detection, and reaction to events. An event represents any significant change in the state of a system, such as a user placing an order or a payment being processed. These events are transmitted to other parts of the system asynchronously, enabling various components to respond in near real-time without direct dependencies.
EDA typically includes three core components:
- Event Producers: Systems or applications that generate events (e.g., a user action or a system update).
- Event Routers: Tools like message brokers (e.g., Kafka, RabbitMQ) that transport these events to the right consumers.
- Event Consumers: Services or systems that react to these events by performing tasks, such as sending notifications or updating records.
This decoupled structure ensures that event producers don’t need to know who consumes their events, fostering a highly modular system architecture (Martin Fowler, Event-Driven Architecture).
The Role of Event-Driven Architecture in Microservices
EDA is particularly valuable in microservices because it allows individual services to communicate without being tightly coupled. Instead of directly invoking each other’s APIs, services emit events representing actions. Other services subscribe to these events and respond as needed. This indirect communication method enhances system flexibility and simplifies service management.
For instance, consider an e-commerce system:
- The order service emits an “Order Placed” event when a user completes a purchase.
- The inventory service listens for this event to adjust stock levels.
- Simultaneously, the notification service sends a confirmation email, while the shipping service begins preparing for delivery.
This design allows these services to function independently while still coordinating efficiently, as proposed by Sam Newman in Building Microservices. This is what decoupling is all about, services can evolve independently, scale, etc…
Benefits of Event-Driven Architecture
- Decoupling: services remain independent, reducing dependencies. For example, a producer like an order service doesn’t need to know which services consume its events, as discussed in Martin Fowler’s article on EDA.
- Scalability: events are processed asynchronously, services can scale independently based on demand. Apache Kafka’s distributed architecture is explicitly designed to handle millions of events per second.
- Responsiveness: systems can react to events in real time. For instance, fraud detection systems can immediately analyze suspicious activity by consuming events from a payment service.
- Resilience: Failures in one part of the system don’t cascade. Events can be queued and retried later, ensuring no critical data is lost. RabbitMQ supports this with its dead-letter queues and acknowledgment mechanisms (ack).
- Extensibility: New services can be added simply by subscribing to existing events, making it easier to evolve the system over time.
- Real-Time Data Processing: Tools like Kafka allow for continuous data streaming, essential for real-time analytics and machine learning workflows. For example, LinkedIn uses Kafka for activity tracking and user recommendations.
Overview of Kafka and RabbitMQ
Apache Kafka
Kafka follows a distributed, publish-subscribe architecture with a few key components:
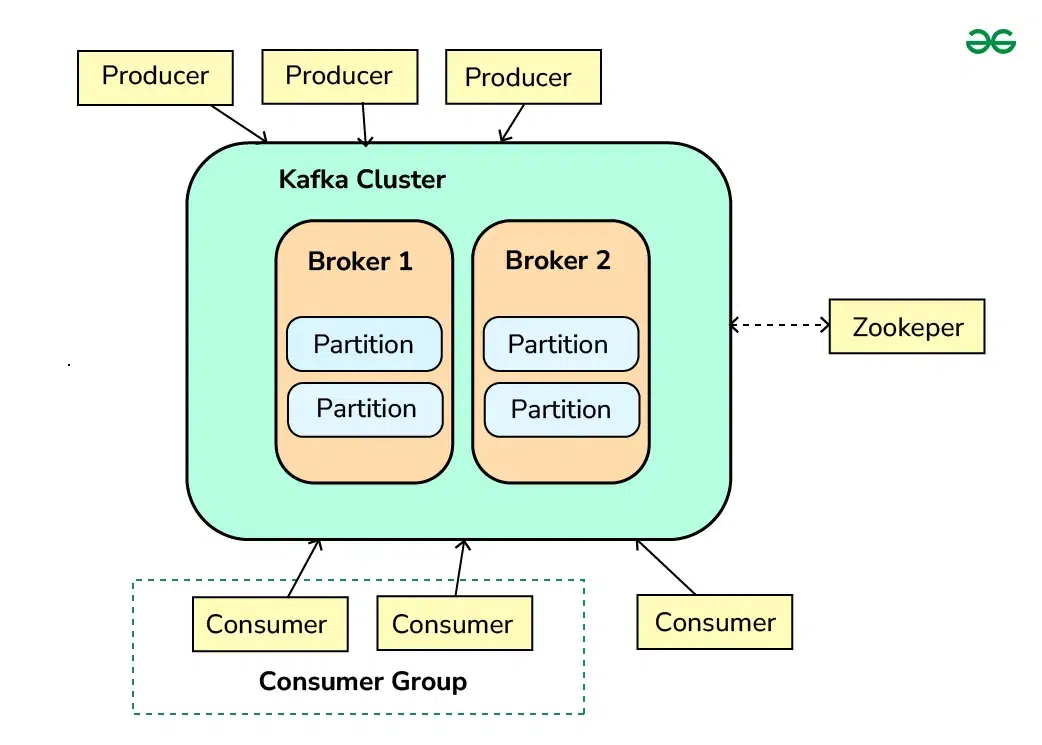
Producer
Any application or service that sends events (messages) to Kafka topics. A kafka producer holds a buffer of unsent records per partition and sends the records to the cluster using an internal batch.size property. In most of the cases the default size could be good enough, but you may want to play around with this value to get a better throughput by increasing the batching. But keep in mind that if the batch size is too big the memory will be wasted since the part of the memory that is allocated for batching will not be used. This happens because the data will be sent before the batch size limit hits. Using a larger batch size makes compression more efficient.
Under heavy loads, batching will probably be in place, however, in light loads data may not be batched until the batch size limit hits, in that case increasing the linger.ms can increase the throughput by increasing batching with fewer requests and with an increased latency on producer send. By default linger.ms is 0, which means no delay. As mentioned previously in Kafka there are multiple broker nodes that holds the same data to enable resilience and availability. By default the producer will wait all replica nodes to return the result because the default value for acknowledgement is all, by setting ack to 1 only the broker that sent the request will send confirmation instead of waiting all in-sync replicas.
Producers can also compress the data before sending it to the broker, this can be done by setting the compression.type property. The compression is done by batch and improves with larger batch sizes. By using compressed data, you can send more data at once through the network and increase the throughput. End to end compression is also possible, this way compression only happens once and is reused by the producer and consumer (better for performance).
Broker
A Kafka Broker is a server (or node) in a Kafka cluster responsible for receiving, storing, and forwarding messages (or events) to consumers. It is a fundamental component of Kafka’s distributed architecture. A Kafka cluster consists of one or more brokers, where each broker is a part of a larger system that stores the actual data (i.e., the events/messages). Each broker is responsible for managing a set of partitions for one or more topics.
Kafka brokers store messages in a distributed manner, partitioning the data across multiple disks for better performance, scalability, and fault tolerance. Kafka brokers receive messages from producers, append them to the appropriate partitions, and handle message delivery to consumers. Brokers handle the replication of data to ensure fault tolerance. Each partition’s data is replicated across multiple brokers to ensure that if one broker fails, data remains available from other brokers in the cluster.
Each partition has one leader broker responsible for handling all read and write operations for that partition. The leader ensures that data is consistently written to the partition, maintains the order of messages, and manages replication. If a producer wants to send a message to a topic, it sends the message to the leader of the corresponding partition.
Followers are brokers that maintain copies of the partition’s data. These replicas are updated with messages from the leader to ensure fault tolerance. Followers do not handle writes; instead, they replicate data from the leader to maintain synchronization. If a follower is too far behind, it may be temporarily excluded from the replication process.
If a leader broker fails, Kafka automatically promotes one of the followers to become the new leader. This process is known as leader election, which is crucial for maintaining high availability. Kafka uses ZooKeeper (in the traditional setup) or KRaft (in newer versions) for leader election and managing partition metadata.
Consumer:
The application or service that reads data from Kafka topics. Kafka relies on logs which are known as partitions, the producers write to the end of a specific partition and the consumers read the logs starting from the beginning while holding an offset to keep track. When it is done with the data, the consumer sends a commit request to the broker so that there will be an offset per consumer per partition, to remember the latest record that was read. This way consumer will continue reading new data instead of reading the same data again.
Each consumer belongs to a consumer group and Kafka distributes partitions to consumers based on these consumer groups. Each partition is strictly assigned to a single consumer in a consumer group, therefore it is not possible to assign the same partition to more than one consumer. This is to prevent conflicts with the offset values and make consuming easier. Different consumer groups with different ids can read the same data form the same partition, so kafka allows you to read the same data more than once, but for that you need to create a new consumer group and read the data again. For maximum concurrency, it is wise to set the consumer number as equal to the partition number. If you create more consumers than partition numbers, after assigning each partition to a consumer, some consumers will be idle and will not read any data.
There is a poll time out in Kafka consumer and setting it to a too high value will make the waiting take longer and cause delays in the application. If the poll time out is too low, the consumer will poll more frequently and this will cause more network traffic and can lead to CPU stall. If you have a single consumer with multiple partitions, there will be no concurrent work on multiple partitions by default (multithreading), but we can still use multiple threads while consuming partitions. This should be implemented on the client side.
When it comes to delivery semantics, Kafka provides three options: at most once, at least once, and exactly once. This behavior relies on the consumer strategy and the ack property on the client side. For example, if you commit after processing the data, the commit operation might fail, but you already processed the data, so in the next poll you will read the same data and it will imply at least once behavior. On the other hand, if you commit before processing the data, you might lose the data if the consumer crashes, so it will imply at most once behavior. Exactly once requires to coordinate between producer and consumer, using transactions starting from the producer part. There is a transaction Kafka API which will start the transaction from producer to use the same transaction in the consumer part. Normally auto commit is set to true on the consumer client, so it does a commit after a configured timer and then reset it. But keep in mind that in some scenarios you might still encounter an error while auto commit is set to true, because a failure can always happen. With this being said, you might need to implement some rollback mechanism or use strict exactly once semantic depending on your needs.
Topic
A Topic is a logical channel or category to which Kafka producers send their messages and from which consumers read their messages. Kafka topics are a fundamental abstraction that organizes messages for efficient routing, storage, and consumption. Topics are essentially message queues to which producers publish data and from which consumers pull data.
Topics help categorize messages by their purpose, such as a “user_signup” topic for user registration events or a “payment_processed” topic for payment-related messages. Consumers subscribe to one or more topics and receive messages (events) that are published to those topics. Kafka follows a publish-subscribe model, where producers publish messages to a topic, and consumers subscribe to topics to receive those messages. A topic can have multiple producers and consumers, allowing for a highly scalable and distributed pub-sub system. Kafka topics are stored on disk, and messages are retained in a topic for a configurable retention period (even after they are consumed, unless manually deleted).
ZooKeeper
Apache ZooKeeper is a distributed coordination service that is used by Kafka to manage and maintain the Kafka cluster. It acts as a centralized service for maintaining configuration information, providing synchronization, and ensuring the integrity of the system.
In earlier versions of Kafka, ZooKeeper was an essential component for managing brokers and maintaining Kafka’s distributed system metadata, such as which broker holds which partition and its leadership. Now newer versions of Kafka are transitioning away from ZooKeeper (Kafka KRaft mode), it is still used in many existing Kafka deployments. ZooKeeper ensures that even if one broker goes down, another broker can take over the responsibility of a partition, thanks to its role in maintaining partition leader information.
KRaft
KRaft (Kafka Raft) is a significant shift in how Apache Kafka manages its cluster metadata and leader election. Traditionally, Kafka used ZooKeeper to manage cluster metadata, including partition leaders, topic configurations, and broker statuses. However, with the introduction of KRaft mode in Kafka, ZooKeeper is no longer required, and Kafka now uses its own internal protocol to manage these responsibilities.
In KRaft mode, Kafka maintains a metadata quorum that is responsible for managing cluster metadata, including topic configurations, partition leadership, and broker statuses. This quorum uses Raft to achieve consensus on metadata changes across all brokers.
The Raft protocol ensures that Kafka’s metadata is consistently replicated across multiple nodes in the cluster. Raft allows Kafka brokers to elect a leader for the metadata quorum, and that leader is responsible for updating metadata and synchronizing changes with follower brokers.
One of the biggest changes with KRaft mode is the removal of ZooKeeper. This drastically simplifies Kafka’s architecture, as Kafka now manages its own leader election and metadata replication without relying on an external service like ZooKeeper. This change reduces operational overhead, makes cluster management more straightforward, and eliminates the complexity of maintaining and configuring ZooKeeper.
Final considerations:
- Transition from ZooKeeper: Migrating from a traditional ZooKeeper-based Kafka setup to KRaft can be a complex process, especially for large and heavily used Kafka clusters. Users must ensure that their applications and systems are compatible with KRaft mode and handle any potential disruptions during the migration.
- New Features and Stability: KRaft mode is still being refined, and certain features that were available with ZooKeeper may take time to fully mature in KRaft. For instance, features like multi-cluster replication and some advanced configurations may not be as mature as in Zookeeper.
- Cluster Scaling: While KRaft simplifies the Kafka architecture, scaling the cluster (both in terms of adding brokers and handling large amounts of metadata) requires careful planning and monitoring. The Raft protocol can introduce its own set of challenges when scaling up a Kafka cluster, especially as the metadata grows more complex.
RabbitMQ
RabbitMQ’s architecture is based on a client-server model and revolves around producers, exchanges, queues, and consumers. These components work together to provide a robust, reliable messaging system.
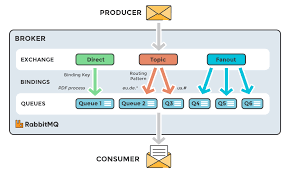
Producer
A Producer is any application or service that sends messages to RabbitMQ. Producers do not directly interact with queues; instead, they send messages to an Exchange, which is responsible for routing the message to the appropriate queue or queues. Producers include a routing key with each message. This key acts as a tag used by exchanges to determine where the message should go. Producers specify the exchange name when sending a message.
If no exchange is specified, RabbitMQ uses the default exchange. Producers send messages without waiting for confirmation that a consumer has processed them, ensuring decoupled communication (although it is possible to wait for the response, but breaks the decoupling).
Exchange
An Exchange is a central routing mechanism in RabbitMQ. It receives messages from producers and determines how to route them to one or more queues based on routing keys and bindings. RabbitMQ supports several types of exchanges, each tailored for specific routing scenarios:
- Direct Exchange: Routes messages to queues based on an exact match between the routing key and the queue’s binding key.
- Fanout Exchange: Broadcasts messages to all queues bound to the exchange, ignoring the routing key.
- Topic Exchange: Routes messages based on pattern matching of the routing key. Patterns use wildcards:
- * matches exactly one word (e.g., log.* matches log.info but not log.error.system).
- # matches zero or more words (e.g., log.# matches log.info and log.error.system).
- Headers Exchange: Routes messages based on custom headers (not the routing key).
Queues
A Queue is a buffer where messages are stored until they are retrieved by consumers. Queues decouple producers and consumers, ensuring that message delivery is reliable even if the consumer is temporarily unavailable. Some of the features of RabbitMQ queues:
- Persistence: Queues can be configured as durable to be able survive broker restarts. This happens because messages are saved to disk.
- Message Priority: Queues can prioritize certain messages to ensure critical tasks are handled first.
- Message TTL: If a message is unconsumed, a Time-to-Live (TTL) can be set to discard it after a given period.
Messages that cannot be routed or are rejected by a consumer can be redirected to a Dead Letter Queue (DLQ) for later inspection or retrying. This is useful for debugging and analyzing failed messages.
Bindings
A Binding is the relationship between an exchange and a queue. Bindings define the rules that exchanges use to route messages to specific queues. Binding keys act as filters for routing messages. For example, a queue bound to a direct exchange with the binding key “error” will receive only messages with a routing key of error. Multiple Bindings is when a single queue can be bound to an exchange with multiple binding keys. This allows the queue to receive messages matching multiple patterns.
Consumers
A Consumer is any application or service that retrieves and processes messages from a queue. Consumers are responsible for ensuring message reliability by acknowledging successful processing.
- Manual Acknowledgment: Consumers explicitly acknowledge each message after successful processing. This ensures that messages are not lost if the consumer crashes during processing.
- Automatic Acknowledgment: RabbitMQ automatically considers the message acknowledged once it is delivered to the consumer. This is faster but less reliable.
Consumers can configure a pre-fetch count to limit the number of messages delivered at a time. This prevents the consumer from being overwhelmed and ensures fair distribution in a multi-consumer scenario.
Broker
The RabbitMQ broker is the server managing the exchanges, queues, and bindings. It ensures that messages are reliably routed and stored as needed. The broker also handles load balancing and fault tolerance.
Other Features
RabbitMQ nodes can form clusters, allowing them to share metadata and distribute workloads across multiple machines. While clusters improve load balancing, queues are hosted by a single node unless explicitly mirrored.
To ensure high availability, RabbitMQ supports mirrored queues, replicating data across multiple nodes. If the primary node fails, a replica takes over to avoid service interruptions.
RabbitMQ can shard queues across nodes, distributing the load and preventing bottlenecks in high-throughput systems.
Routing mechanisms like dynamic routing, priority queues and dead-letter exchanges provide flexibility in message handling and delivery.
Kafka vs. RabbitMQ
When deciding between Apache Kafka and RabbitMQ for your microservices architecture, it’s crucial to understand their core differences. Below is a comparison based on various aspects like message models, use cases, scalability, durability, and routing.
Kafka is designed as a distributed log system that streams messages in real time. It follows a publish-subscribe model, where producers write messages to topics, and consumers read them independently. Kafka retains messages for a specified duration regardless of consumption, enabling replayability for debugging and analytics. Kafka is ideal for high-throughput, real-time use cases such as:
- Event sourcing in microservices.
- Real-time analytics pipelines.
- Log aggregation across distributed systems.
- Use in industries like finance (stock), retail (inventory updates), and for sensor data streaming.
RabbitMQ operates as a traditional message broker with a focus on message queuing. Producers send messages to an exchange, which routes them to queues based on bindings. Consumers then process messages, and once acknowledged, they are removed from the queue. RabbitMQ prioritizes reliable delivery over retention. Here are some use cases where RabbitMQ is commonly used:
- Asynchronous task execution (e.g., sending emails, processing images).
- Workload balancing across multiple consumers.
- Systems where message ordering and routing flexibility are critical.
In terms of scalability and performance, Kafka’s partitioned, distributed architecture makes it highly scalable. Topics are divided into partitions spread across brokers, allowing for parallel processing. It achieves millions of messages per second but requires significant setup and infrastructure. On the other hand, RabbitMQ scales well within a single cluster but has limitations at extreme throughput levels. It uses mirrored queues and sharding for scalability but typically handles hundreds of thousands of messages per second, focusing on reliability over raw speed.
When it comes to durability and message retention, Kafka retains messages for a configurable time (e.g., days or weeks), irrespective of consumption. This log-based retention ensures that even if a consumer fails, it can replay messages from the past, making Kafka suitable for event sourcing and data reprocessing. RabbitMQ ensures message durability by persisting messages to disk. However, once a message is acknowledged, it’s removed from the queue. This makes RabbitMQ more suitable for workflows where message replay is not required.
For routing and flexibility, Kafka relies on its topic-based publish-subscribe model for routing. Messages are routed to topics, and consumers subscribe to specific partitions. This simplicity makes Kafka less flexible for complex routing scenarios. RabbitMQ offers advanced routing options through exchanges (direct, fanout, topic, headers). These options allow developers to implement complex routing rules, making RabbitMQ highly versatile.
Error Handling and Dead Letter Queues (DLQs)
Kafka
- Message Failures: Kafka’s approach is based on retries and offset management. If a consumer fails to process a message, it can adjust its offset to reprocess the message. This makes error handling flexible but relies on developers to implement the correct retry logic.
- Dead Letter Queues: Kafka doesn’t natively support DLQs but provides mechanisms to implement them. For example, failed messages can be redirected to a separate “dead letter topic” using stream processing frameworks like Kafka Streams or with a custom consumer.
RabbitMQ
- Message Failures: RabbitMQ includes built-in support for message acknowledgments. If a consumer fails to acknowledge a message, RabbitMQ can requeue it for a configurable amount of times or send it to a Dead Letter Exchange (DLX).
- Dead Letter Queues: RabbitMQ’s DLX is an exchange where rejected messages are routed. This feature is straightforward to configure by setting specific queue parameters (x-dead-letter-exchange) to handle undeliverable messages.
Message Ordering and Idempotency
Kafka
- Ordered Processing: Kafka ensures ordering within a partition. Producers decide the partition for each message, and messages within the same partition are processed in the order they arrive. Consumer groups distribute partitions among consumers, maintaining order at the partition level.
- Idempotency: Kafka supports idempotent producers to ensure that duplicate messages are not produced, even in retry scenarios. This is particularly useful for applications that require strict once-only delivery semantics.
RabbitMQ
- Ordered Processing: RabbitMQ does not guarantee message ordering, especially when using multiple consumers for a queue. Message ordering can break due to acknowledgments being processed out of sequence or consumer distribution.
- Idempotency: RabbitMQ leaves idempotency handling to the application layer. Developers must implement mechanisms to detect and handle duplicate messages, often by using unique message identifiers.
Replication and Disaster Recovery
Kafka
- Partition Replication: Kafka ensures high availability through partition replication. Each partition has a leader and multiple followers. If the leader fails, one of the followers takes over.
- Failover Scenarios: Kafka’s ZooKeeper (or KRaft in newer versions) automatically manages leader election during failover. This ensures minimal disruption to message processing.
RabbitMQ
- Mirrored Queues: RabbitMQ offers mirrored queues to replicate messages across multiple nodes. If the primary node fails, a replica can take over.
- Failover Scenarios: Failover in RabbitMQ depends on clustering. While it provides high availability, managing clusters can be complex, especially for large-scale deployments.
Hybrid Architectures
Hybrid architectures leverage the strengths of both Kafka and RabbitMQ to handle diverse requirements in a system. Instead of viewing Kafka and RabbitMQ as competitors, this approach integrates them to balance scalability, reliability, and functionality across various workloads. Let’s dive deeper into how this is achieved and explore specific examples, challenges, and best practices. I’m not a guru in this field, but in my mind makes sense we would use the best of both worlds. I didn’t find many information about this topic, but I’ll try to make the best of it.
Hybrid architectures are beneficial because Kafka and RabbitMQ complement each other in terms of their core functionalities. Kafka shines in high-throughput scenarios that require real-time event streaming, distributed logging, and analytics. On the other hand, RabbitMQ is ideal for managing reliable, task-based messaging and handling point-to-point communication with advanced routing features. By using both tools, systems can take advantage of Kafka’s strengths in event streaming and RabbitMQ’s strengths in task management and message routing, leading to an architecture that optimizes performance, reliability, and scalability.
When you need to handle diverse workloads, hybrid architectures provide the flexibility to use the right tool for the job. For instance, systems that require both real-time data processing and reliable task delivery can leverage Kafka for the data streaming aspects and RabbitMQ for the task management, ensuring that each function operates at its best.
In a hybrid setup, Kafka and RabbitMQ interact in different ways depending on the specific needs of the system. One common pattern is to use Kafka for real-time event streams and RabbitMQ for task-based messaging. Kafka can process high-throughput events such as tracking user interactions or processing sensor data, and then RabbitMQ can take over to manage tasks like sending notifications, updating databases, or performing background processing based on those events.
In an e-commerce platform, Kafka could be responsible for streaming real-time customer behavior data, such as page views, cart interactions, and purchases. This data can be used to power recommendation engines or provide marketing insights. Meanwhile, RabbitMQ could handle the actual order processing tasks like confirming payment, updating inventory, and sending emails or notifications to customers.
Although it looks powerful, I think it would have some challenges. First, managing two systems can increase complexity. Kafka, with its distributed nature and partitioned topic structure, is fundamentally different from RabbitMQ’s queuing and task-based model. As a result, maintaining such an architecture requires expertise in both systems.
Data synchronization can also be a challenge in hybrid architectures. Ensuring that data flows consistently and smoothly from one system to the other requires careful consideration, especially if messages are produced faster than they can be consumed.
Monitoring and troubleshooting become more complex as well. Since Kafka and RabbitMQ are different tools with their own set of metrics and logging structures, effective monitoring requires using multiple tools to track both systems. It’s critical to implement a unified monitoring system that can track events across both Kafka and RabbitMQ to avoid performance bottlenecks and ensure smooth operations.
In the Real World
Apache Kafka
Netflix uses Apache Kafka for its real-time event streaming needs, to stream, process, and analyze this data in real-time. This enables capabilities like monitoring user activity, delivering personalized recommendations, and improving the system logging and diagnostics.
LinkedIn, the creator of Kafka, uses it as the backbone for its activity streams. Kafka ensures high-throughput message delivery across LinkedIn’s services, such as tracking user interactions, delivering notifications, and supporting the real-time flow of information across its platform.
Uber integrates Kafka to handle its real-time trip-tracking and pricing mechanisms. Uber’s platform generates streams of events, such as driver location updates and customer requests. Kafka processes this data in real-time to power features like dynamic pricing, which adjusts fares based on demand and supply, and to ensure that ride status updates are instantaneously reflected in the app.
RabbitMQ
Airbnb relies on RabbitMQ for task queuing and reliable communication between its microservices. RabbitMQ ensures that critical tasks, such as confirming bookings or processing payments, are delivered and processed reliably even under high system load. This guarantees that no message is lost, making it an essential component.
Mozilla employs RabbitMQ as part of its telemetry system. RabbitMQ handles millions of daily messages from Firefox users, which include performance data and error logs.
Instagram uses RabbitMQ to manage asynchronous task processing, such as sending notifications, processing media uploads, and moderating content.
| Use Case | Description | Tool | Real-World Example |
|---|---|---|---|
| Real-time Analytics | Processing large volumes of streaming data for dashboards and insights. | Kafka | Netflix for viewing trends and recommendations. |
| Task Queue Management | Asynchronous task processing where reliability and acknowledgment are critical. | RabbitMQ | Instagram for notifications and media processing. |
| Event Sourcing | Capturing state changes as events to rebuild system state for auditability and reprocessing. | Kafka | Uber for trip lifecycle management. |
| Microservices Communication | Enabling decoupled communication between microservices for scalable applications. | RabbitMQ | Airbnb for managing inter-service communication in booking systems. |
| Log Aggregation | Collecting and centralizing logs from distributed systems for analysis. | Kafka | LinkedIn for operational monitoring and debugging. |
| Data Pipelines | Streaming data from multiple sources to storage and processing systems. | Kafka | Spotify for streaming user interactions to analytics platforms. |
| Data Streaming | Handling high-frequency data from devices in real-time. | Kafka | Tesla for collecting telemetry data from vehicles. |
| Dynamic Pricing | Adjusting prices in real-time based on demand and supply. | Kafka | Uber for surge pricing models. |
| Notification Systems | Sending real-time notifications to users across platforms. | RabbitMQ | Instagram for user notifications on new messages and updates. |
| Financial Transactions | Ensuring reliable message delivery for payment systems. | RabbitMQ | Stripe for managing payment workflows securely. |
| Content Moderation | Processing and flagging inappropriate content asynchronously. | RabbitMQ | Reddit for detecting and moderating flagged user posts. |
| Supply Chain Tracking | Monitoring inventory levels and logistics in real-time. | Kafka | Walmart for real-time inventory updates across stores. |
| Gaming Leaderboards | Streaming player activity data to generate real-time leaderboards. | Kafka | League of Legends for updating player rankings dynamically. |
Conclusion
Choosing between Apache Kafka and RabbitMQ isn’t just a technical decision—it’s about understanding the system’s needs and aligning those with the strengths of each tool. In my opinion, both are strong and mature tools, but they shine in different ways, and that’s what makes this comparison so interesting. It actually very interesting to understand how each architecture and structure have an impact on the usages of each tool.
Kafka is like the powerhouse you call when you need to stream massive amounts of data in real-time, analyze it on the fly, and handle large amounts of data (million messages per second is no joke). It’s built for distributed systems, thrives in high-throughput environments, and is perfect for use cases like real-time analytics, data streams, and event sourcing. Its log-based retention and replayability make it an event-driven architecture perfect match. But let’s be real—it’s not the easiest tool to learn or manage, especially when you’re diving into topics, partitions, replication, and the complexities of ZooKeeper or KRaft. I’ve made a repository on event driven architecture with Kafka, and I can say that it was a challenge to understand the concepts and implement them. I still have a lot to learn about Kafka, but I think I’ll get there!
RabbitMQ, on the other hand, is all about simplicity and reliability. It’s the go-to tool for task queues, asynchronous job processing, and microservices communication when you need messages delivered and acknowledged. Its flexibility with exchanges and protocols gives you all the routing options you could ask for, and it’s far easier to set up and use compared to Kafka. I’ve used RabbitMQ on a project I’m developing with a friend and the setup, the structure and the concept are much easier to understand and implement in comparison to Kafka. However, it’s not designed to scale in the same way Kafka is, and for scenarios involving massive data streams or real-time analytics, it might not be the smartest choice.
At the end of the day, it’s all about the problem you’re solving. I know that this is a cliche, but it’s the truth! In the IT world is actually something that we have to keep in mind at all times, because the tools are not just tools, we need to have a good understanding of how they work to make informed choices. With that being said, if you’re building a scalable system to handle high-throughput, low-latency event streams, Kafka is your pick. If you’re managing complex routing and reliable message delivery between services, RabbitMQ might be a better fit. And if you’re somewhere in between, it’s worth considering whether these two tools can coexist in your stack, although it might add some complexity to your architecture.
The goal isn’t just to pick the “best” tool but the right tool for your unique requirements. So, take a step back, think about your architecture, your team’s expertise, and the future scale of your system. And if you’re still stuck? Maybe it’s time to build a proof of concept and see these tools in action. Because at the end of the day, nothing beats real-world experimentation when it comes to figuring out what works best. This is one of the things that I learned in my journey as a developer, the best way to learn is by doing and discussing with experienced people.