The Rise of Reactive Programming with Spring WebFlux - A Game Changer or Overkill?
Reactive programming has sparked a revolution in the realm of software development. With its capacity to efficiently handle large-scale, highly concurrent systems, it has become the go-to approach for building modern, responsive applications. In the world of Java development, Spring WebFlux has emerged as a formidable framework, offering developers the tools they need to harness the power of reactive programming.
In this article, we embark on a journey through the landscape of reactive programming and its impact on the world of Java development. We’ll delve into the core principles that define reactive programming and explore how it transforms the way we approach application design. We will focus on Spring WebFlux, the driving force behind reactive Java applications, as we examine its capabilities and shed light on why it has gained momentum in recent years.
Understanding Reactive Programming
Right now, in the IT community, the term “Reactive” is getting a little bit overloaded/abused, so according to the Reactive Manifesto (https://www.reactivemanifesto.org), the reactive systems are Responsive, Resilient, Elastic and Message Driven. The term “reactive” in the context of programming models revolves around the idea of reacting to change, such as components responding to various events like I/O or user input. Feel free to read the manifesto for a better understanding of this concepts.
Complex systems are built from smaller, interconnected components, and their behavior hinges on the responsiveness of these constituent elements. This implies that Reactive Systems employ a set of design principles to ensure that these responsive properties are consistently exhibited across all levels of scale within the system, enabling seamless composability. In essence, every building block, whether large or small, is designed to exhibit reactive characteristics, allowing them to work in harmony and combine effectively to create a cohesive and adaptable system.
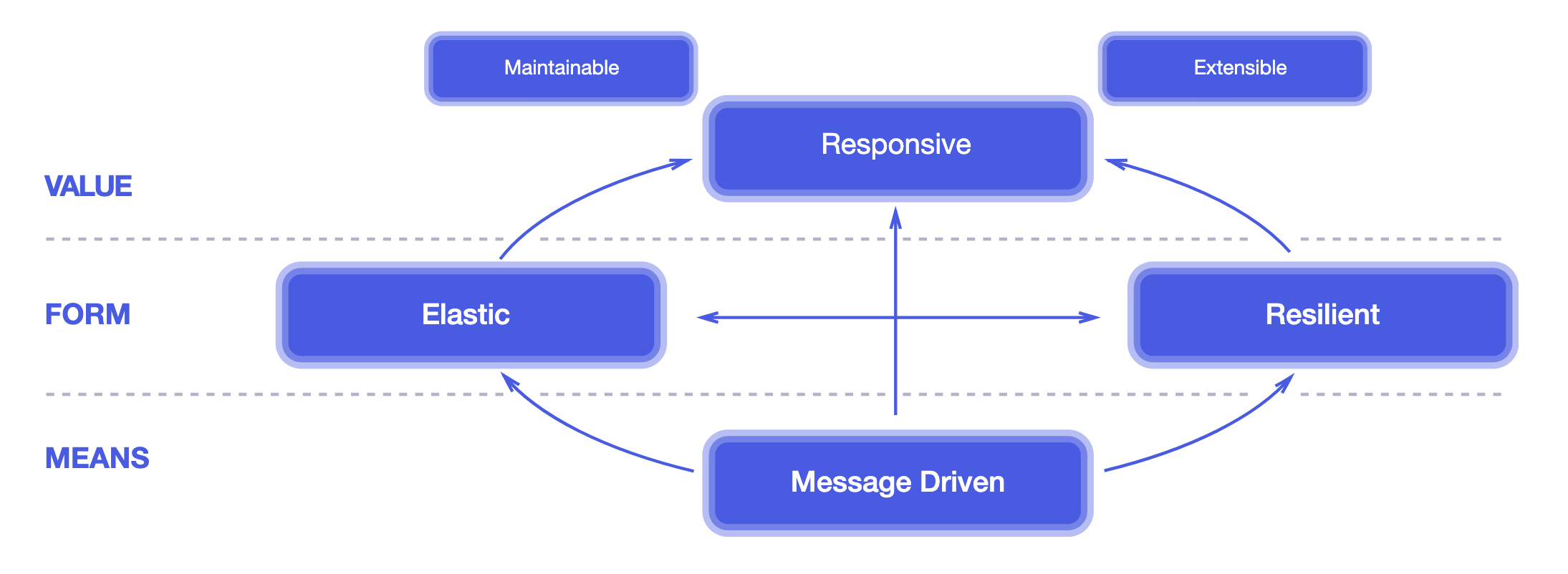
Now that we have a better understanding of what the term “Reactive” really stands for, we can dive into Reactive Programming. Reactive programming is an implementation technique, a tool, that focuses on non-blocking, asynchronous execution, a key characteristic of Reactive Systems.
Reactive programming is an asynchronous programming paradigm focused on streams of data an events in a non-blocking way. According to Gerad Berry, a French Computer Scientist, these programs also maintain a continuous interaction with their environment, not the program itself. Interactive programs work at their own pace, while reactive programs only work in response to external demands. That being said, the first one, tends to block threads, leading to performance bottlenecks and decreased system responsiveness. In contrast, the second one, uses non-blocking I/O operations, allowing applications to handle more requests concurrently with a faster response time.
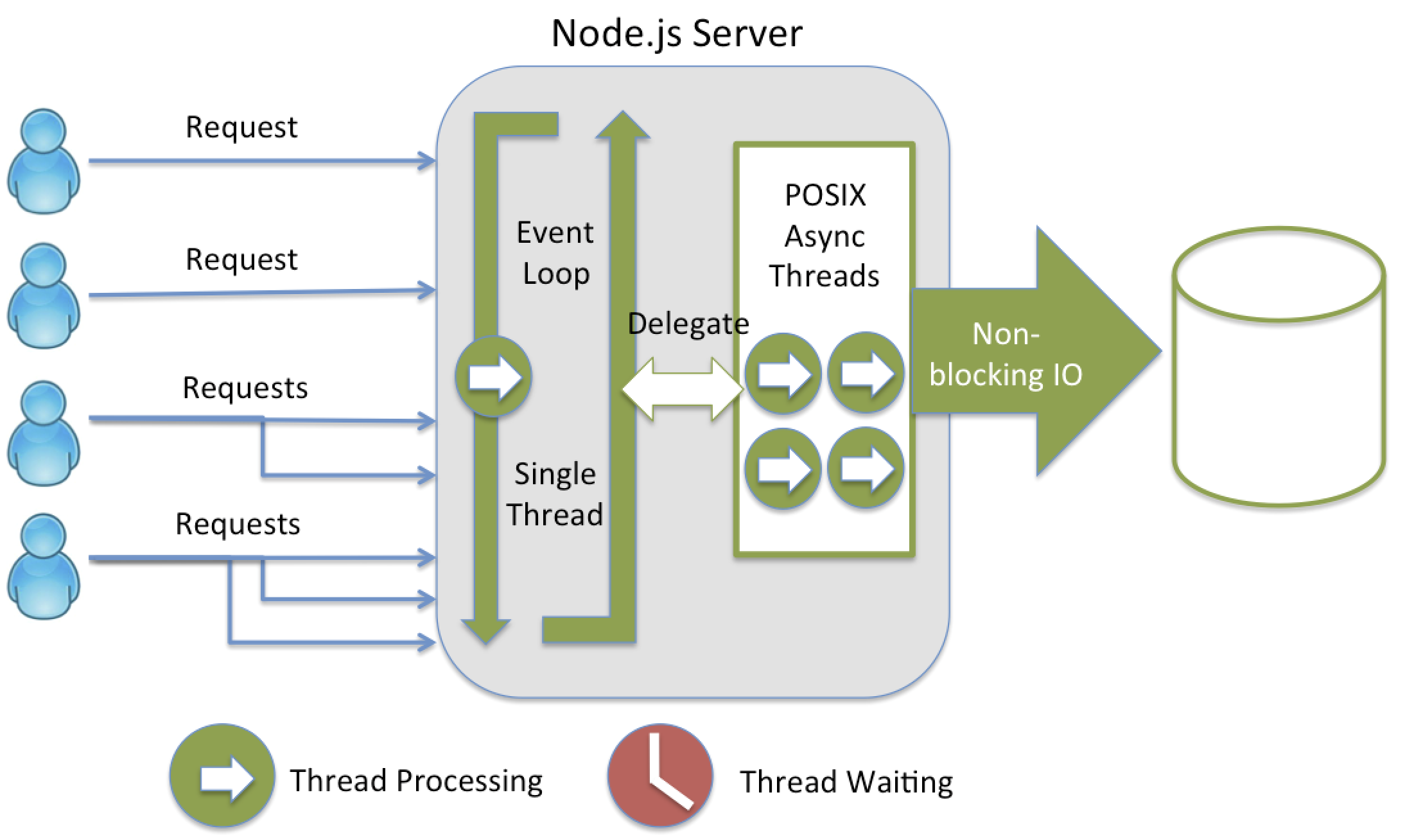
The Non-blocking concept is very important. In Blocking, the code will stop and wait for more data (ie reading from disk, network, etc). Non-blocking in contrast, will process available data, ask to be notified when more is available and then continue. In the images below, we can have a better understanding of what Non-blocking consists.
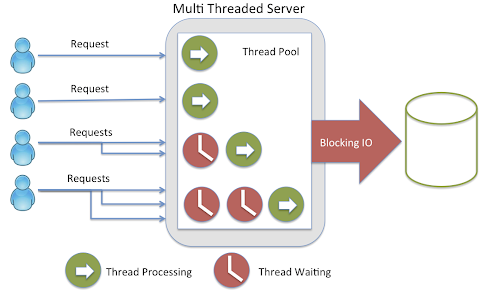
Java developers always have been pretty comfortable using Multi Threaded Servers, where we have a thread pool that take a given number os requests. When a given thread receives a request, it will get suspended while is waiting for a resource. This starting and stopping of the threads is pretty common and Java handles it very efficiently, so its not necessarily a bad programming paradigm and it has been around for a long time.
In contrast, we have the Node.js server that uses different techniques to manage the threads. In the Figure 3 above, a request comes in and we have a single thread in loop to the the work, that delegates the requests to async threads as they come in. As we can see we have no waiting threads, at all times all the threads are processing, which can improve efficiency and performance. But this isn’t properly a good thing, imagine that something on the event loop takes a lot of CPU, that can really bring down Node.js performance, not to talk about the callback hell that Node.js is known for. It is a significantly different paradigm because your requests are expected to complete quickly on that event loop and get off of it.
Another feature of reactive programming is the Back Pressure. Back Pressure is the ability of the subscriber to throttle data, to help avoid issues as buffering and blocking. Throttling is the practice of controlling the quantity of data that can be exchanged between two systems within a specific time frame. Typically, this is implemented to avoid one system overwhelming another with an excessive data load or to ensure that an individual user does not excessively deplete a shared resource. The failures are also a little different as well, since exceptions are not thrown in a traditional sense, since it would break the stream. Exceptions are processed by a handler function.
What is Spring WebFlux?

WebFlux is a reactive programming model for building web applications and is a part of the Spring Framework ecosystem. Based on the documentation, it was created with two primary needs: Concurrency and Resource Efficiency and Functional Programming. It is built on top of the Reactive Streams API, which provides a model to build web applications on the JVM.
Reactor is the reactive library for Spring WebFlux. It offers the Mono and Flux API types to work with data sequences of 0 to 1 and 0 to many, using a comprehensive set of operators aligned with the ReactiveX operator vocabulary. As a Reactive Streams library, Reactor ensures support for non-blocking back pressure.
Spring WebFlux has two main components: the RouterFunction and the HandlerFunction. The RouterFunction serves the purpose of associating incoming requests with their corresponding HandlerFunction. The role of the HandlerFunction is to manage the request and provide a response. The objective of the Reactive Stream API is to create a standard for asynchronous stream processing with a non-blocking back pressure. There are two main components: the Publisher and the Subscriber. The publisher emits the data and the subscriber consumes it.
For instance, a data repository acting as a Publisher can produce data, while an HTTP server acting as a Subscriber can write this data to the response. The primary purpose of Reactive Streams is to enable the subscriber to control the pace at which the publisher produces data, ensuring a balanced flow of information.
Spring WebFlux & Spring MVC
I think by now we can have a pretty good idea where both of these paradigms differ. Although they’re both designed to build web applications, one uses a blocking approach and the other one uses a non-blocking approach. Spring Web MVC traditionally incorporates the servlet API and operates within a servlet container, which are by nature blocking as well as JDBC and JPA. In Spring WebFlux, the web server does not use the servlet container, because it is using a new stack underneath that. Although Spring made a really good job keeping it abstract to us developers, we must keep in mind that Web MVC components are blocking!
But the real question is: which one is better? Is Spring WebFlux that good has it seems to be? And the answer is simple, it depends. I know, cliché, but its my honest opinion and a lot of times, especially in Software Engineering, is actually true. We can’t choose one over the other based only on this, we need to be skeptical and understand what are the needs of the program we are about to develop. That being said, let’s take a look at where and when one paradigm can be better than the other.
Spring WebFlux
Spring WebFlux is ideal for applications that need to handle a large number of concurrent requests and require high scalability. For example, a high-traffic e-commerce website, that needs to handle a large number of concurrent requests. If your application deals with streams of data or events, such as real-time updates, IoT devices, or message-driven architectures, WebFlux enables handling of asynchronous operations and provides built-in support for WebSocket communication. It’s also really good with microservices and if your team is into functional programming, it will be worth your while for sure!
Spring MVC
Spring MVC is a suitable choice when your application primarily handles synchronous request processing and doesn’t require the high concurrency and scalability benefits of reactive programming. Spring MVC has a widely adopted and mature ecosystem, making it a dependable choice for many applications. The existence of heavy dependency on Spring MVC libraries or if the project relies on blocking I/O operations, migrate it to Spring WebFlux can be tricky. It really comes down to the needs of your existent program and the experience of the team you’re working with, sometimes Spring MVC is the way to go.
Performance Considerations
In my GitHub profile, I have repositories where I used Spring MVC and where I used Spring WebFlux and thats the reason I’m writing this article, to share my journey and what I could learn while doing it. So, if we take into consideration the performance of both approaches, we can take this example of my projects.
Let’s consider a scenario where we need to handle multiple concurrent requests for fetching data from a remote service. We’ll compare the performance of Spring WebFlux and Spring MVC in this situation.


In the WebFlux example, when a non-blocking request is made, the server thread efficiently manages other incoming requests while it awaits the response. This capability empowers the server to handle a larger number of concurrent requests, all with a reduced need of numerous threads. This results in a significant enhancement in scalability, as the server can efficiently serve multiple clients simultaneously.
On the other hand, in the MVC example, synchronous requests are processed, and the server thread remains engaged until the response is received. This conventional approach poses limitations on the number of concurrent requests the server can effectively manage. Consequently, this method may experience performance degradation when subjected to high workloads, as the server’s resources can become bottlenecked due to the blocking nature of request processing.
According to a Medium post, where they compare WebFlux to Web MVC, the Spring Boot (threadpool), Spring WebFlux demonstrates noticeable performance advantages, particularly in terms of requests per second and response times. It achieves approximately double the RPS compared to Spring Boot while maintaining a similar resource cost. The performance characteristics differ based on concurrency levels. At lower concurrency levels, Spring WebFlux exhibits superior median response times. However, at higher levels of concurrency, Spring Boot outperforms Spring WebFlux. Feel free to read their post and analyze their research.
But keep in mind, reactive and non-blocking programming may not inherently make applications run faster. They can enhance performance in certain scenarios, such as when using WebClient for parallel remote calls, but typically, they entail more complex implementation and may slightly increase processing time. Never the less, their primary advantage lies in the ability to scale effectively with a fixed number of threads and reduced memory usage. This scalability improves application resilience under heavy loads, offering more predictable performance. The true benefits of reactive and non-blocking become apparent in situations with latency, including slow and unpredictable network, where the reactive approach excels and can lead to significant performance improvements.
The Final Verdict
The moment we were all waiting for: the verdict. At least mine. After reading multiple posts of other fellow developers and enthusiasts, some think that Reactive Programming isn’t that big of a deal and others think it will take Java to the next level. Throughout this section I will try to be as impartial as possible, so we can actually take something from this and make up our own minds.
Let’s start with the concept of Non-Blocking, if we need to make a call, then block to wait for the response and then handle the response because we need that same thread, we can’t and we’re not using Reactive, because we can get into an event loop and stop the application. What I’m trying to say is that everything that uses ThreadLocal, the Java special class that allows us to store data that will be accessible only by a specific thread, is not compatible with reactive. You might think “That isn’t that big of a deal, just don’t use it!”, well I’m afraid that sometimes it might not be possible. Like I said before, JDBC, for example, is intrinsically blocking, its not something we can switch on and off. It is dependent of the ThreadLocal to allow rollbacks, because it holds the transaction, and if we’re working with old JDBC databases, migration can be painful (trust me). The database driver must use the R2DBC spec in order to work with non-blocking calls. One important thing to mention, that sometimes can go unnoticed, is fact that REST calls aren’t blocking, because, in Spring WebClient, they’re not thread-dependent, meaning that the request thread doesn’t have to be the response thread.
If f your application is already handling loads efficiently using traditional MVC or by resorting to horizontal scaling, it may not be the most prudent business decision to opt for WebFlux. In such cases, the additional complexity and resource allocation required by WebFlux might outweigh the potential benefits it offers, making it less compelling from a cost-benefit perspective. So reactive and non-reactive paradigms cannot be mixed, which means that the application has to be reactive end to end. It’s not impossible, but integrating blocking code into a reactive pipeline can be challenging for what I could gather and is an anti-pattern approach for me. Not to talk about debugging, the process that we learnt in the first day of college can become quite hard if the pipeline isn’t correctly built.
Apart from the performance benefits, I found it cognitively complex, hard to read nested code, hard to debug and divides the ecosystem efforts. It’s hard enough to keep complicated synchronous code working and adding the complexity of these non-blocking apis only further complicates already complicated code. This could have been the projects issue. By harder to maintain I mean adding certain features. Sometimes this required to rewrite whole chains instead of simply adding to the existing code. Plain imperative sequential code is much much easier to reason about, and therefore maintain and evolve, than reactive code. This can lead to a team spending more time having to fix technical issues than they are adding business value and for someone who doesn’t have that much experience like me, the code can be unreadable, unlike other approaches that even though we’re not used to we can get around.
As i was scavenging the internet, I began to understand that almost everyone doesn’t really need reactive, they think it will be the savior and it will resolve all their performance problems. Well that’s most definitely not true, WebFlux is used for very specific needs where the advantages surpass the downsides. And with the rise of Loom Project, these APIs begin to stay behind. I strongly recommend you to check out the Loom project, it can be a game changer. While I remain skeptical that Loom will serve as a silver bullet solution for these issues, I do hold the hope that the adoption of more linear control flows will enhance the readability and writability of code. There’s a certain comfort in following the familiar path of writing straightforward imperative code. Additionally, with the impending arrival of Virtual Threads, the value proposition of transitioning to a reactive approach appears to be somewhat diminished. These advancements lead me to question whether the adoption of reactive programming is as compelling as it once was.
In a nutshell, if you find yourself in a position where you are willing to make a trade-off, sacrificing a degree of simplicity in exchange for the potential performance enhancements, then embracing reactive programming could be a strategic decision that aligns with the specific needs and goals of your project. It’s an approach that allows you to harness the power of asynchronous, non-blocking operations to cater to high-concurrency scenarios, thereby unlocking new possibilities for your application’s scalability and responsiveness.